
Der er ved at ske et skifte i måden, hele internettet håndterer AI-trafik på. Det er større end en produktopdatering. Cloudflare, der sidder foran mere end 20 procent af nettets domæner, er ved at gøre op med den model, der har finansieret …

Der er ved at ske et skifte i måden, hele internettet håndterer AI-trafik på. Det er større end en produktopdatering. Cloudflare, der sidder foran mere end 20 procent af nettets domæner, er ved at gøre op med den model, der har finansieret nettet i næsten 30 år, og bygge systemet om fra bunden.
For dig viser det sig som noget meget konkret: standarderne for, hvilke AI-bots der må hente indhold fra din hjemmeside, ændrer sig til september, og på nogle hjemmesider kan det betyde, at Google og Bing pludselig bliver blokeret. Vi sidder i en lidt speciel position med det her, for vi udgiver selv content og bygger samtidig AI-agenter, der besøger andres hjemmesider. Så vi ser begge sider af bordet.
Hvad er Content Independence Day egentlig?
For at forstå ændringen skal vi et år tilbage. Den 1. juli 2025 kaldte Cloudflare det Content Independence Day. Argumentet var enkelt. I næsten 30 år kørte nettet på én uskreven aftale: søgemaskiner måtte kopiere dit indhold, og til gengæld sendte de besøgende tilbage til dig. Den trafik kunne du tjene på, via annoncer, abonnementer eller bare ved at nå din målgruppe.
AI brød den aftale. En AI-crawler henter dit indhold, men sender ingen tilbage. Svaret genereres direkte i chatten, og brugeren klikker aldrig ind på din side. Cloudflares reaktion var kontant: de gjorde det muligt at blokere AI-crawlere med ét klik, og de lancerede en Pay-Per-Crawl-markedsplads, hvor AI-firmaer kunne betale for adgang.
Et år senere, den 1. juli 2026, er tonen en anden. Ikke fordi problemet er løst, men fordi "bloker alt AI" viste sig at være for stumpt et værktøj. Contentejere vil stadig beskyttes og betales for deres arbejde. Men de vil også kunne findes. Og der er stor forskel på en bot, der stjæler din tekst til modeltræning, og en bot, der henter din side for at besvare en konkret brugers spørgsmål lige nu. Derfor deler Cloudflare nu AI-trafikken op, og det er kernen i det hele.
Hvorfor gør de det? Tallene bag
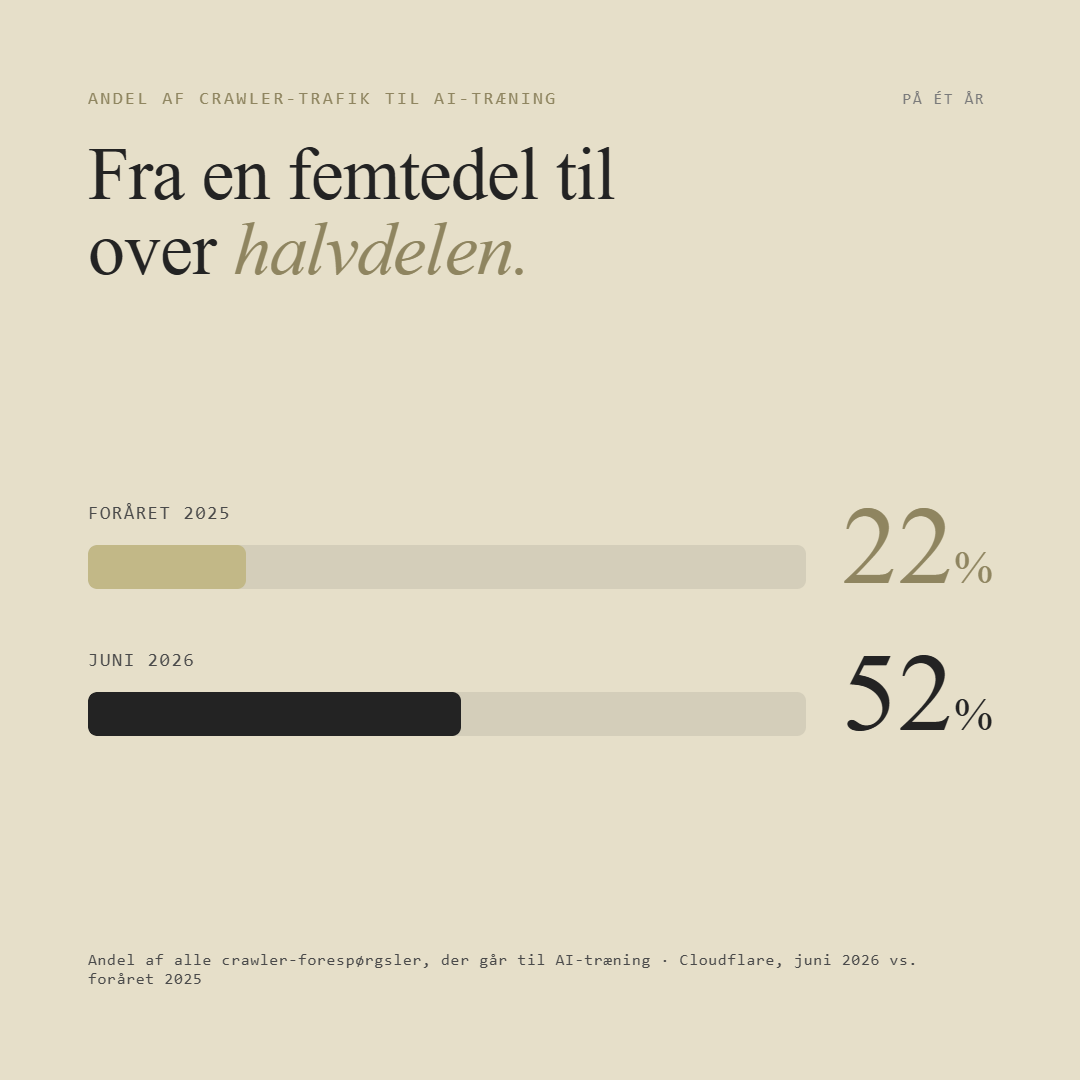
Det korte svar: crawltrafikken er eksploderet, og den er blevet skæv. Ifølge Cloudflares egne tal går 52 procent af alle crawlerforespørgsler nu til AI-træning, målt i juni 2026. Til sammenligning var det 22 procent i foråret 2025. På godt et år er træning altså gået fra en femtedel til over halvdelen af al crawling.
Samtidig er en stor del af bottrafikken blevet svær at gennemskue. Crawlere med flere formål, der både laver søgning og træning på én gang, står for over 36 procent af aktiviteten. Det, der virkelig gør ondt på contentejere, er forholdet mellem hvor meget der bliver hentet, og hvor lidt der kommer retur. Cloudflare målte omkring sidste års Content Independence Day forhold mellem crawls og henviste besøgende på alt fra 118 til 1 og helt op mod 50.000 til 1.
Med andre ord: en AI-crawler kan have hentet din bedste artikel titusinder af gange for at sende dig én enkelt besøgende. Og problemet stopper ikke ved de rene AI-firmaer. Google selv er blevet en svarmaskine. Et Pew Research-studie fra 2025 fandt, at når Google viser et AI-resumé øverst, klikker brugeren kun videre til et almindeligt søgeresultat 8 procent af gangene, og på et link inde i resuméet blot 1 procent.
Her ligger den knude, der har fået Cloudflare til at gøre noget. Google bruger en crawler med flere formål, hvor søgning og AI hænger sammen i samme bot. Det betyder to ting for dig som contentejer. Du kan ikke deltage i Googles søgning uden også at fodre Googles AI, og du kan ikke se, om et besøg fra Google gik til søgning eller til et AI-svar. Den sammenblanding giver Google adgang til cirka dobbelt så meget information som de førende AI-firmaer, vurderer Cloudflare.
Det er også baggrunden for, at EU-Kommissionen i december 2025 åbnede en formel konkurrencesag om netop Googles brug af content til AI, og at forlaget Penske Media har lagt sag an i USA. Kort sagt bliver du bedt om at vælge mellem at være synlig og at blive udnyttet. Cloudflare forsøger at give dig et tredje valg.
De tre kategorier: Search, Agent og Training
I stedet for at diskutere, hvad der tæller som AI (en definition, der ændrer sig hver måned), stiller Cloudflare nu et mere brugbart spørgsmål: hvad laver botten egentlig på min side? Det gav tre kategorier, som alle kunder kan styre hver for sig, også på gratisplanen.
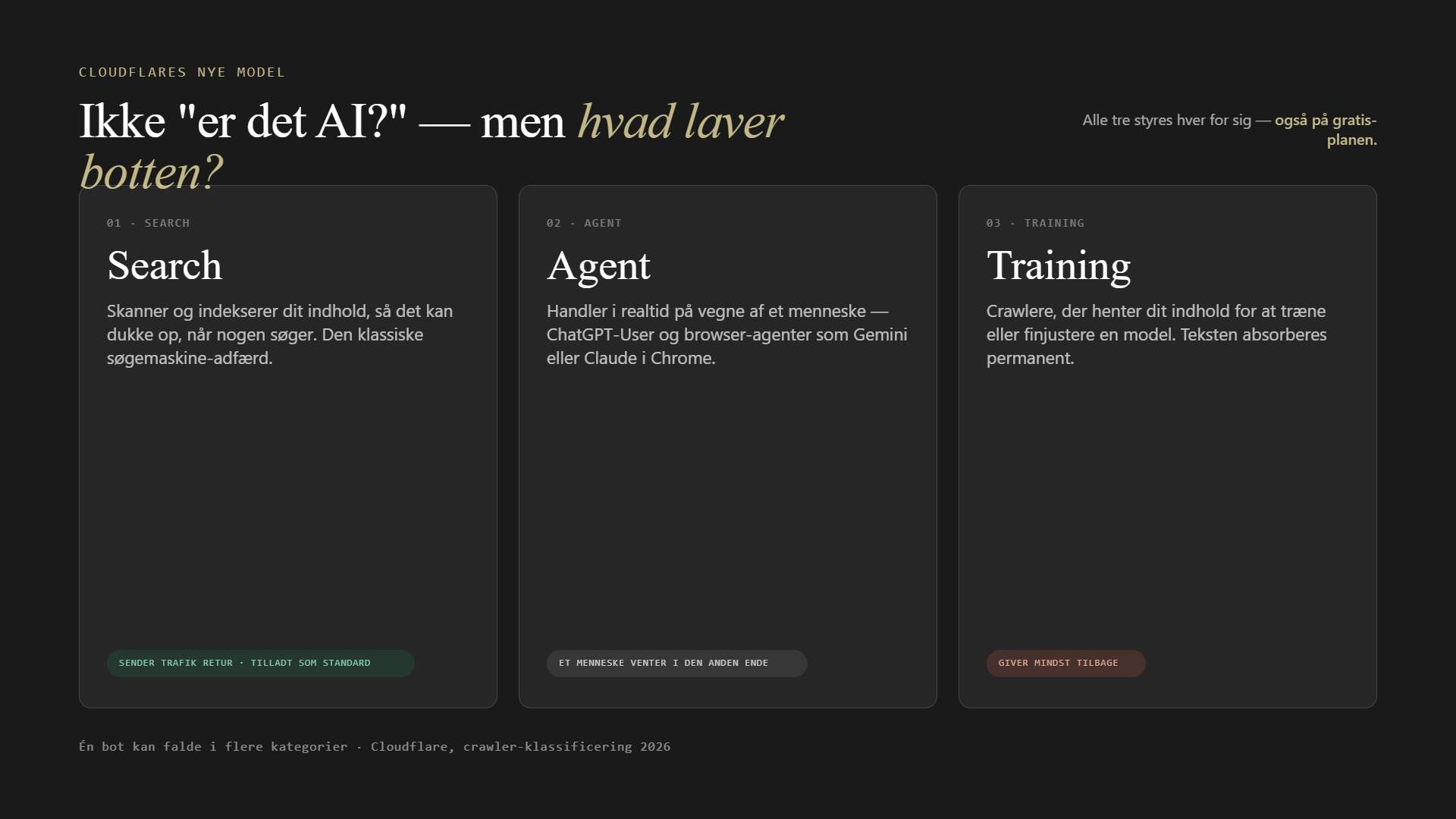
Search er bots, der skanner og indekserer dit indhold, så det kan dukke op, når nogen søger. Det er den klassiske søgemaskineadfærd. Den sender typisk trafik retur, og derfor forbliver Search tilladt som standard.
Agent er bots, der handler i realtid på vegne af et menneske. Nogen har stillet et spørgsmål eller bedt om en opgave, og agenten henter din side for at løse den her og nu. Eksemplerne fra Cloudflare er blandt andet ChatGPT-User og browseragenter som Gemini eller Claude, der styrer en Chrome-browser. Der sidder som regel et rigtigt menneske og venter i den anden ende.
Training er crawlere, der henter dit indhold for at træne eller finjustere en model. Din tekst bliver permanent absorberet ind i modellen. Det er den kategori, der giver mindst tilbage.
Ud over de tre klassificerer Cloudflare også en række andre formål fra din hverdag: Transact (en agent, der gennemfører et køb), Data Collection (prisscraping og konkurrentovervågning), SEO-værktøjer, Ads Verification, feedhentning til RSS og podcasts, linkpreviews på sociale medier og driftsovervågning. Men de tre AI-kategorier er dem, alle kunder nu kan skrue på direkte. En vigtig detalje: en enkelt bot kan falde i flere kategorier, og det er præcis dét, der gør den næste del vigtig.
Hvad ændrer sig helt konkret den 15. september?
Der sker to ting, og den anden er den, du skal være vågen på. Den første ændring: for alle nye domæner, der kobles på Cloudflare, bliver Training og Agent blokeret som standard, men kun på de sider, der viser annoncer. Search forbliver tilladt. Logikken er, at en annonce er et signal om, at du har tænkt en rigtig person skulle lande på siden. På de sider holder Cloudflare de bots ude, der spiser af den menneskelige opmærksomhed uden at sende noget retur.
Den anden ændring er den, der kan bide: bots med flere formål bliver bedømt på alt, de laver. Fremover bliver en crawler med flere formål vurderet ud fra samtlige af sine formål, ikke kun ét, og den mest restriktive regel vinder. Hvad betyder det i praksis? Googlebot, Applebot og BingBot laver både søgning og træning. Hvis du har valgt at blokere Training, bliver de tre altså også blokeret.
Det gælder, uanset om du har sat det op via de nye kategoriindstillinger, eller om du bare har den gamle Block AI bots slået til fra sidste år. Læs den sidste sætning en gang til, hvis du har en Cloudflare-konto. Har du på et tidspunkt trykket Block AI bots for at holde ChatGPT væk fra dit indhold, så begynder den samme indstilling efter 15. september også at spærre Googles og Bings søgecrawlere. For en hjemmeside, der lever af organisk trafik, er det at save den gren over, man sidder på.
Det er ikke Cloudflares hensigt at ramme din SEO. Det er en konsekvens af, at de nu behandler bots med flere formål ærligt. Men konsekvensen er reel, og den udløses automatisk, medmindre du gør noget.
Sådan sætter du det op, eller framelder ændringen
Den gode nyhed: du bestemmer selv, og det tager få minutter. Funktionen Block AI bots ligger i Cloudflares nye application security-dashboard. Log ind på Cloudflare og gå til Security Settings, og gør det direkte i dashboardet frem for via linket i en mail. Filtrér på Bot traffic, og gå til Block AI bots.
Under Configurations trykker du på rediger-ikonet og vælger mellem tre muligheder. Du kan blokere AI-bots kun på de dele af sitet, der viser annoncer (Cloudflare finder selv ud af, hvilke subdomæner der har annoncer), du kan blokere på alle sider, eller du kan slå blokeringen helt fra. Tryk Save. Vil du blokere enkelte navngivne crawlere i stedet for hele grupper, bruger du Cloudflares AI Crawl Control.
Vil du beholde tingene præcis, som de er i dag, altså framelde de nye standarder? Så markerer du det i dine Security settings når som helst inden 15. september. Det bekræfter, at du ikke vil have ændringer på de Training-crawlere, der også crawler for Search. Vores anbefaling er enkel: log ind og kig efter, hvad der står tændt, før du beslutter noget. De fleste opdager, at de ikke havde tjek på det.
Det tekniske lag: robots.txt, Content Signals og content-use
Er du til den tekniske side, bliver det her interessant. Cloudflare bygger videre på robots.txt, men tilføjer to nye lag. Det første er Content Signals, en udvidelse af din robots.txt, hvor du udtrykker en præference i stedet for en hård blokering. En Cloudflare-styret robots.txt kan for eksempel sætte search til yes, ai-train til no og use til reference. Altså: søgning er ok, træning er ikke, og indholdet må bruges på reference-niveau.
Det bringer os til det andet lag, content-use, som handler om, hvad en bot må gemme og gengive, efter den har hentet din side. Der er tre niveauer. Immediate betyder, at botten må interagere, men ikke gemme eller genbruge noget. Reference betyder, at den må indeksere, citere uddrag og linke tilbage, og det er standard. Full betyder, at den må opsummere og gengive i fuld længde.
De to lag kan kombineres med kategorierne til ret præcise regler, for eksempel at tillade alle bots til Search, SEO og Ads Verification, men kun op til reference-niveau. Det lader dig styre i fornuftige grupper i stedet for bot-for-bot. Vigtigt: værdierne i robots.txt er præferencer, ikke blokeringer. De signalerer, hvad du ønsker. Til gengæld begynder Cloudflare at spore content-use for hver bot, og en bot, der misbruger signalerne eller gengiver i fuld længde, kan miste sin Verified-status og dermed sin adgang.
Nyt til de større setups: BotBase, business-tal og transitive trust
Kører du et Enterprise-setup, kommer der et par tunge tilføjelser. BotBase er Cloudflares nye database over samtlige kendte bots og agenter, søgbar direkte i dashboardet. Du kan se, hvordan hver bot er klassificeret efter adfærd, filtrere din egen trafik ned til en enkelt bot og kopiere dens detection-ID til brug i dine Security rules. Det er første gang, det fulde katalog vises dynamisk i dashboardet.
Attribution Business Insights er et dashboard for dem, der skal tage forretningssnakken uden at læse regelsyntaks. Det viser dit crawl-til-referral-forhold, både for hele sitet og per botoperatør, over 24 timer, 7 dage eller 30 dage. Formålet er at give dig fakta med til bordet: at kunne fortælle et AI-firma, at deres crawlvolumen er tyve gange større end en konkurrents, der allerede betaler dig for adgang.
Verified-status er blevet omdefineret. Før var alle verificerede bots tilladt som standard. Nu gør Verified-mærket blot en bot tilladelig via sin relevante kategori. Det er altså den tilladte kategori, ikke selve mærket, der afgør adgangen. Til gengæld åbner Cloudflare processen op, så flere botoperatører kan blive verificerede på en mere gennemsigtig måde.
Transitive trust er det mest fremadskuende. Den bot, der banker på din dør, er i stigende grad ikke bygget af det firma, der sender den. En platform kan køre automatik for tusindvis af udviklere, du aldrig har hørt om. Cloudflare foreslår at bruge den eksisterende Forwarded-header fra RFC 7239 til at bære tilliden med gennem alle mellemled. Siger du tillad denne operatør, holder præferencen, uanset om operatøren kommer direkte eller gennem tre lag af betroede mellemled. At miste betroet status på tværs af de mere end 20 procent af nettets domæner, der ligger bag Cloudflare, gør ondt nok til at betyde noget.
Den anden side: hvad hvis du selv kører AI-agenter?
Her taler vi af egen erfaring. Vi bygger agenter, der besøger andres sider, blandt andet via Claude i Chrome og en række MCP-servere, og med den nye Agent-kategori bliver de bots påvirket, når de rammer annoncesider hos folk, der har slået Training og Agent fra.
For dig, der eksperimenterer med agentiske workflows, betyder det tre ting. Dine agenter kan begynde at få afvist adgang steder, hvor de før kom ind, og et pludseligt 403-svar kan skyldes præcis denne ændring frem for en fejl i din kode. Gennemsigtighed bliver en fordel, for Cloudflare belønner operatører, der er ærlige om, hvem de er, og hvad de gør med indholdet, blandt andet via metoder som Web Bot Auth. Og hele retningen peger mod en verden, hvor det at være åben om sin adfærd giver mere adgang, ikke mindre.
Det er faktisk den mest interessante del af hele udmeldingen. Cloudflare forsøger at bygge et tillidssystem, hvor ærlighed kan betale sig for begge parter. Contentejeren får kontrol og indsigt. Den velopdragne agent får adgang. Den, der slører sine hensigter, mister den.
Bonus: markedet bevæger sig fra crawl til svar
En sidste ting værd at holde øje med. Sideløbende med botkontrollerne har Cloudflare åbnet ventelisten til en Monetization Gateway, hvor du kan tage betaling for en hvilken som helst side, et datasæt, et API eller et MCP-værktøj bag Cloudflare. Betalingen afvikles i stablecoins over den åbne x402-protokol, uden at du selv skal bygge en betalingsløsning.
Samtidig flytter tankegangen sig fra at tage betaling per crawl til at betale per svar. Ræsonnementet er teknisk velbegrundet. Forskning fra ETH Zürich i april 2026 viste, at over 90 procent af de sider, store crawlere behandler, er unikke i indhold, hvilket bryder de cachingantagelser, nettet var bygget på. Og over halvdelen af crawltrafikken bruges på at hente sider, der ikke har ændret sig siden sidst. Ved at signalere, hvad der rent faktisk er nyt, kan man spare AI-firmaet for compute og dig for båndbredde, og samtidig betale dig, når dit indhold faktisk bliver brugt i et svar.
Det er stadig tidligt. Men retningen er klar. Når en agent søger dusinvis af gange for at besvare ét spørgsmål, er hverken crawlet eller klikket den enhed, der tæller. Det er resultatet.
Hvad bør du gøre nu?
Her er det korte, hvis du kun læser ét afsnit. Log ind på Cloudflare og tjek dine botindstillinger, og kig specifikt efter, om Block AI bots er slået til på nogen af dine domæner. Har du blokeret AI eller Training, så forstå konsekvensen, for efter 15. september rammer det også Google, Bing og Apple, og så må du beslutte, om det er det, du vil. Vil du beholde status quo, så frameld de nye standarder i Security settings inden 15. september.
Overvej også at bruge annonce-muligheden bevidst. Skal AI-bots kun holdes ude fra dine annoncesider, eller fra hele sitet? Det er sjældent det samme svar. Og tænk længere end blokering, for trafikken fra klassisk søgning falder, uanset hvad du gør med dine bots.
Det sidste punkt er det, vi bruger mest tid på sammen med kunder. Botindstillingerne er en knap, du skal have styr på. Men den egentlige opgave er at forstå, hvad AI gør ved din synlighed, og hvordan du bygger content og forretning, der stadig holder, når nettet ikke længere sender de klik, det plejede. Har du brug for hjælp til at gennemgå dit setup eller lægge en plan, så tag fat. Det er præcis den slags, vi laver.
Fortsæt læsningen
906 kald senere: Hvad køber du egentlig for mere effort i Opus 4.8?
En praktisk analyse af kvalitet, tokenforbrug og svartid, målt på et almindeligt Claude-abonnement, ikke i et laboratorium. Datagrundlag: 90…

Når Washington kan slukke din AI: Anthropic, OpenAI og Europa
Først tvang den amerikanske regering Anthropic til at slukke sine to stærkeste AI-modeller fra den ene dag til den anden. Nu har den gjort d…

Kan man vækste organisk via AI blot med llms.txt?
For 8 uger siden lagde en dygtig dansk B2B-mand et opslag op, som rigtig mange nikkede til: gør en llms.txt-fil dig mere synlig i ChatGPT, C…