
De fleste AI-sprogværktøjer taler 100 sprog nogenlunde. Vi ville bygge et, der taler ét sprog rigtig godt. Resultatet er en retskrivningsassistent, der kører 100 % lokalt på en enkelt computer, retter dansk grammatik efter Dansk Sprognævns …

De fleste AI-sprogværktøjer taler 100 sprog nogenlunde. Vi ville bygge et, der taler ét sprog rigtig godt. Resultatet er en retskrivningsassistent, der kører 100 % lokalt på en enkelt computer, retter dansk grammatik efter Dansk Sprognævns officielle regler og forklarer hver eneste rettelse med paragrafhenvisning.
Systemet bygger på en open source-sprogmodel (Gemma 4 Medium fra Google), der er finetunet med 58.000 dansk-specifikke eksempler hentet direkte fra Dansk Sprognævns materialer. Ovenpå modellen har vi bygget tre uafhængige valideringslag, et RAG-system, der slår op i Retskrivningsordbogen i realtid, og en diff-baseret forklaringsmotor, der genererer deterministiske, korrekte paragrafhenvisninger. I dette indlæg åbner vi motorhjelmen og viser præcis, hvordan det hele hænger sammen.
Problemet vi ville løse
Når en dansk virksomhed bruger ChatGPT eller lignende cloud-tjenester til at korrekturlæse tekst, opstår der tre problemer på én gang. For det første forlader teksten virksomheden og ender på en server i USA, hvilket skaber juridiske udfordringer omkring GDPR og databehandleraftaler. For det andet er generelle sprogmodeller generalister, der taler mange sprog "fint", men som ikke har dyb specialviden om dansk retskrivning. Og for det tredje koster cloud-AI penge pr. forespørgsel, hvilket gør det dyrt ved høj volumen.
Vi satte os for at løse alle tre problemer samtidig. Målet var klart: et system, der kører 100 % lokalt (ingen data forlader maskinen), der følger Dansk Sprognævns officielle regler (ikke bare "lyder rigtigt"), og som forklarer sine rettelser pædagogisk (så brugeren lærer af det).
Resultatet er en pipeline med fem hovedkomponenter: en finetunet sprogmodel, et RAG-lag med Retskrivningsordbogen, tre valideringslag med hver sin specialitet, et retry-system, der giver modellen en ny chance ved grammatiske fejl, og en diff-baseret forklaringsmotor. Lad os tage dem én ad gangen.
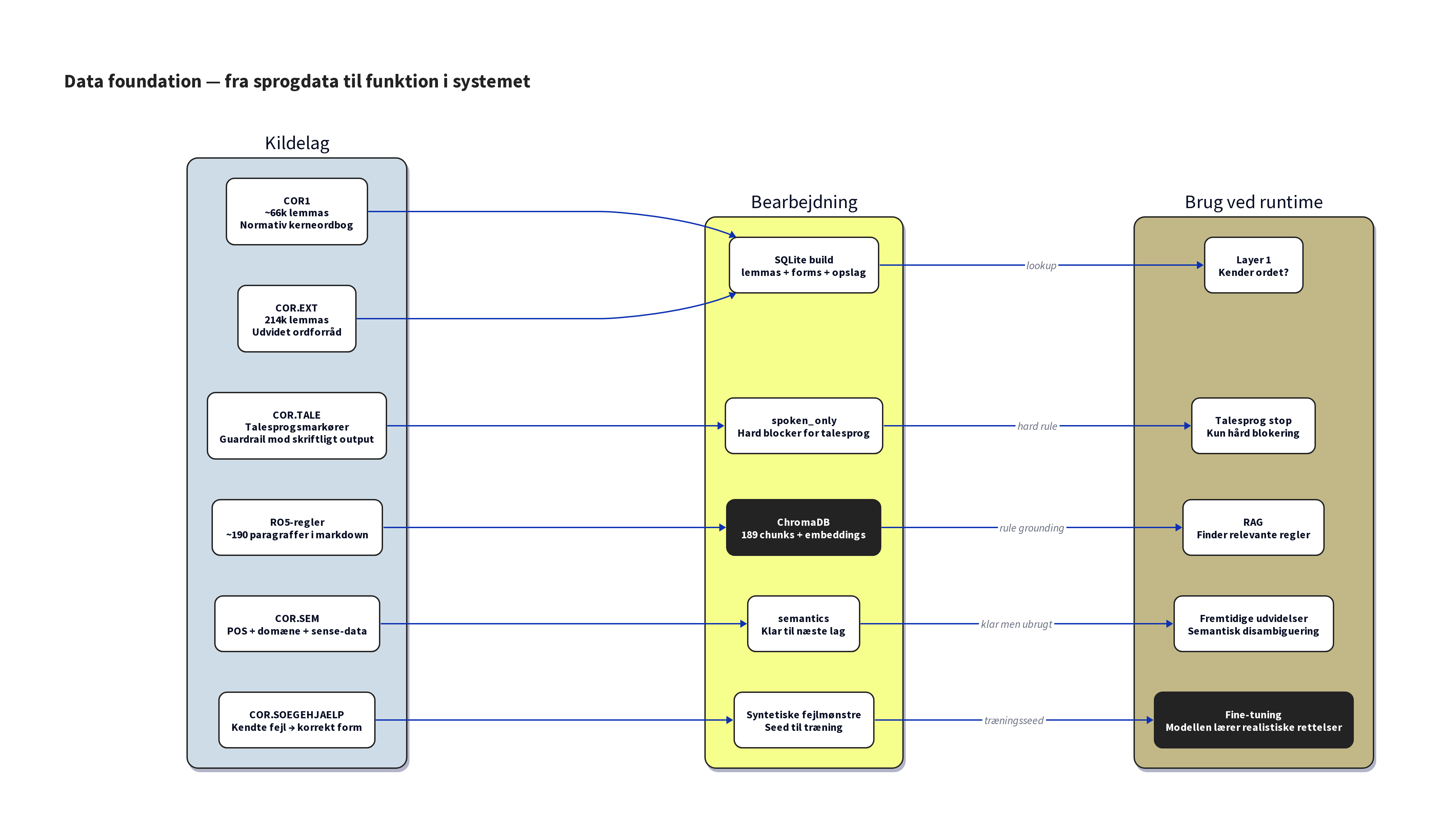
Datafundamentet - 749.000 ordformer og 189 regelchunks
Et AI-system er kun så godt som de data, det bygger på. Vores system hviler på to søjler: Dansk Sprognævns officielle ordbogsdata og retskrivningsreglerne i digital form.
Fra COR-databasen (det fælles digitale ordbogskorpus bag Retskrivningsordbogen) har vi bygget en lokal SQLite-database med ca. 749.000 bøjningsformer fordelt på ca. 280.000 lemmaer. Databasen indeholder både kerneordforrådet fra Retskrivningsordbogen (ca. 66.000 opslagsord med alle godkendte bøjninger) og et udvidet ordforråd fra Den Danske Ordbog (ca. 214.000 lemmaer med fagtermer, afledninger og komposita). Hvert opslag har bøjningsform, morfologisk beskrivelse og normativ status, så systemet kan skelne mellem fx "synes" (nutid) og "syntes" (datid) på et strukturelt niveau.
Retskrivningsreglerne (RO5, 5. udgave) er konverteret til markdown og opdelt i 189 chunks efter paragrafstruktur. Hver chunk er embedded med en flersproget embedding-model (bge-m3, 1024 dimensioner) og gemt i en vektordatabase. Chunking-strategien følger dokumentets egen struktur: H3-niveau (paragrafnumre) er den primære grænse, og lange paragraffer splittes videre på H4-niveau. For at forbedre søgekvaliteten er hver chunk beriget med aliaser, så fx paragraffen om nutids-r også matcher søgetermer som "vi køre eller vi kører" - noget den formelle paragraftekst ikke indeholder.
Derudover indeholder COR-data en tabel med 9.000 kendte stavefejl (fx "syntes" brugt i stedet for "synes" i nutidskontekst). Disse fejlpar har vi brugt som frø til at generere syntetisk træningsdata.
Fine-tuning - fra generalist til dansk specialist
Basismodellen er Googles Gemma 4 Medium, en open source-sprogmodel. Den er kompetent på mange sprog, men den er en generalist. For at gøre den til en specialist i dansk retskrivning, trænede vi den videre (fine-tuning) med 58.287 omhyggeligt validerede eksempler.
Hvert eksempel består af tre dele: en fejlbehæftet dansk tekst, den korrekte version og en forklaring med paragrafhenvisning. Eksemplerne er genereret syntetisk med udgangspunkt i de 9.000 kendte fejlpar fra COR-databasen og derefter valideret automatisk: hvert eneste ord i den korrigerede tekst blev slået op i COR-databasen, og eksempler med ukendte ord blev kasseret. Af 60.285 genererede eksempler bestod 58.287 valideringen (96,7 %).
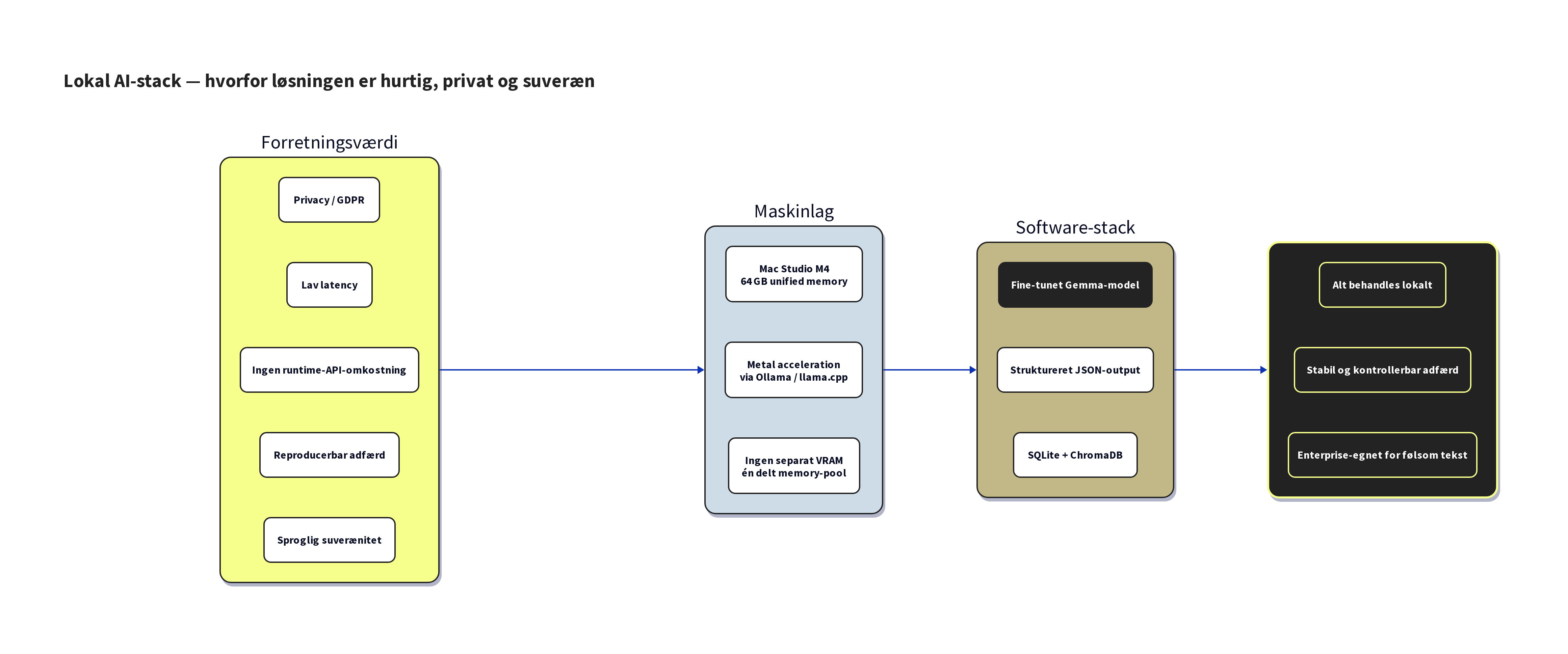
Selve finetuningen brugte LoRA-teknikken (low-rank adaptation), som tilføjer små, trænbare adaptere ovenpå den frosne basismodel. Træningen kørte 1.000 iterationer direkte på Apple Silicon via MLX-frameworket og bragte tab fra 3,16 til 0,24. Adapternes størrelse er kun 178 MB, men effekten er markant: modellen gik fra at være en sprogmodel, der "kan lidt dansk", til en specialist, der konsekvent retter nutids-r-fejl, kommatering og sammensatte ord.
Efter træning blev modellen kvantiseret til Q8_0-format (8-bit), hvilket reducerer størrelsen til 5,8 GB uden væsentligt kvalitetstab. Vi valgte bevidst ikke mere aggressiv kvantisering (4-bit eller 5-bit), fordi maskinen har 64 GB RAM, og kvalitetsforskellen ikke er den sparede plads værd. Modellen importeres i en lokal inferensserver og er klar til brug uden internetforbindelse.
Runtime - fem trin fra rå tekst til rettet output
Når en bruger sender en tekst ind, gennemløber den fem trin. Hele processen tager typisk 10-30 sekunder, afhængigt af tekstens længde.
Trin 1: RAG-opslag. Inden modellen overhovedet ser teksten, analyserer systemet den med en simpel heuristik: indeholder teksten potentielle nutids-r-fejl? Sammensatte ord? Ledsætninger, der kræver komma?
Baseret på analysen sammensættes en søgeforespørgsel, der henter de 10 mest relevante paragraffer fra Retskrivningsordbogen.
Disse paragraffer injiceres i modellens prompt, så den har de præcise regler foran sig, når den retter. Det er her RAG-mønsteret (Retrieval-Augmented Generation) kommer ind: modellen gætter ikke på reglerne, den ser dem.
Trin 2: LLM-korrektion. Teksten sendes til den finetunede model med de hentede regler som kontekst. Modellen returnerer struktureret JSON med en rettet tekst. Et centralt designvalg her er schema-håndhævet output: inferensserveren tvinger modellen til at producere valid JSON på token-niveau, hvilket eliminerer formateringsfejl fuldstændigt. Temperaturen er sat til 0,1 (næsten deterministisk), fordi retskrivningsregler normalt har præcis ét korrekt svar.
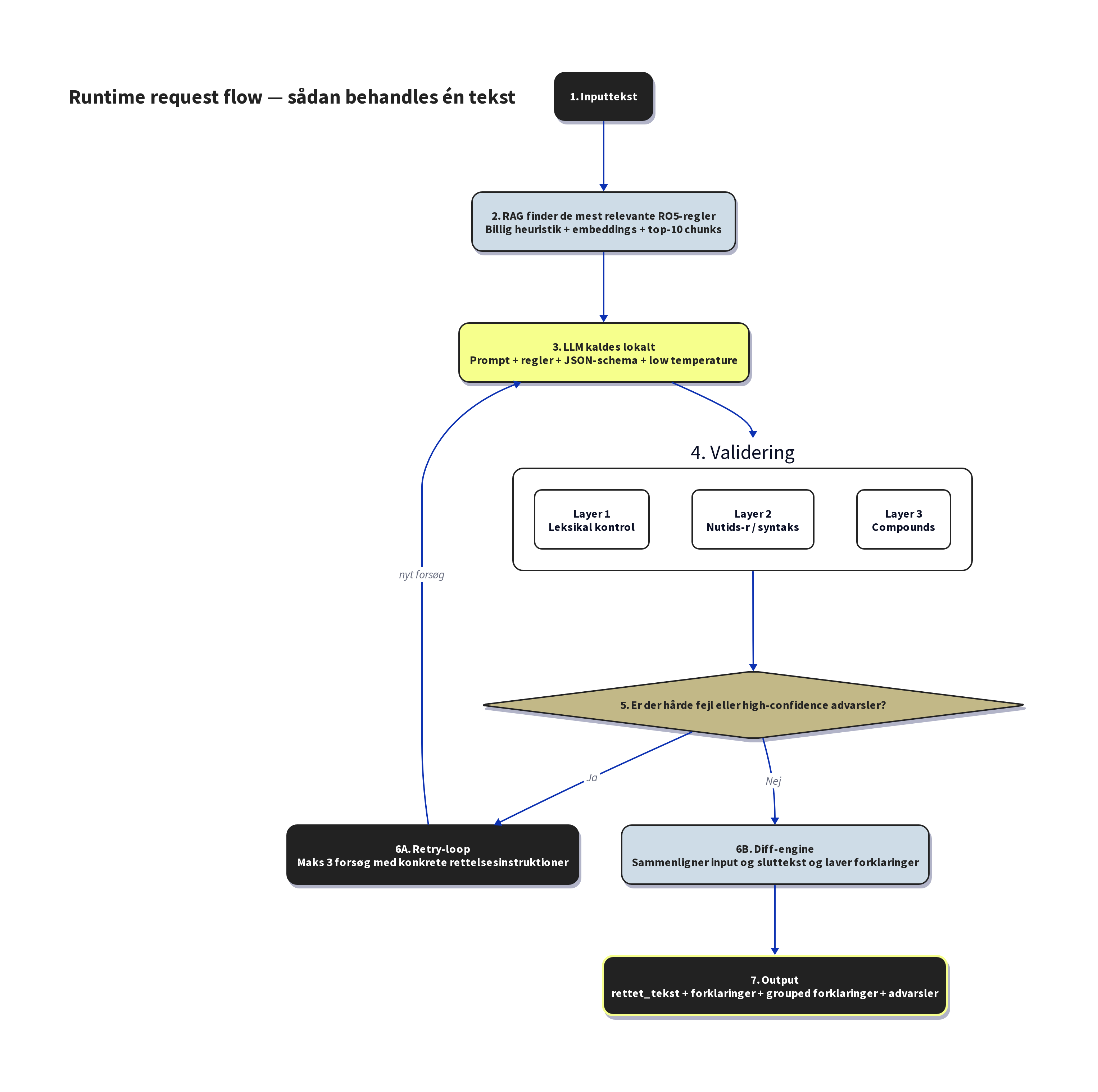
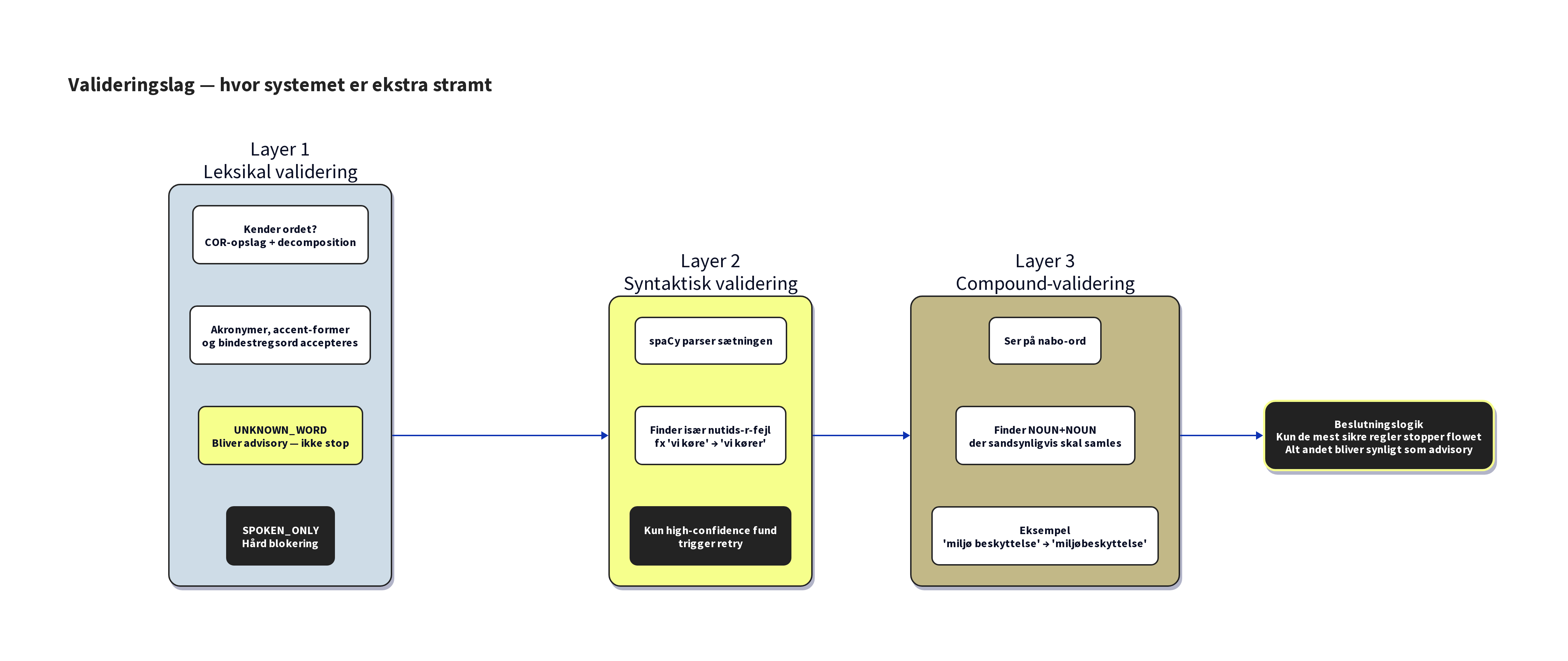
Trin 3: Tre-lags validering. Modellens output valideres af tre uafhængige "korrekturlæsere":
Lag 1 (leksikal validering) slår hvert ord i den rettede tekst op i COR-databasen. Hvis et ord ikke genkendes, markeres det som en advarsel, men teksten blokeres ikke. Fagtermer, egennavne og engelske låneord (som "USPTO", "on-prem" eller "embedding") får lov at passere. Kun talesprog ("sgu", "ka'") er en hård blokering.
Lag 2 (syntaktisk validering) bruger NLP-parsing til at fange nutids-r-fejl. Algoritmen er sofistikeret: den parser sætningens dependency-træ, tjekker om verbet er i infinitivposition, undersøger om der er et modalverbum ovenfor i træet (fx "vi kan køre" er korrekt), og krydsvaliderer mod COR-databasen for at sikre, at præsensformen faktisk eksisterer. Kun når alle gates clearer, rapporteres en fejl med høj konfidens.
Lag 3 (compound-validering) fanger sammensatte ord, der fejlagtigt er skrevet i to ord. For hvert tilstødende navneordspar (NOUN+NOUN) tester systemet, om sammenskrivningen (med eller uden fuges) er en kendt COR-lemma. Hvis ja, rapporteres det.
Trin 4: Retry-loop. Hvis lag 2 eller lag 3 finder fejl med høj konfidens, sendes teksten tilbage til modellen med en handlingsorienteret prompt: "Ordet 'køre' mangler nutids-r, ret det til 'kører'." Modellen får op til tre forsøg. I praksis leverer den i 90 % af tilfældene korrekt output første gang, og retry-loopet aktiveres kun i 10 % af forespørgslerne.
Trin 5: Diff-baseret forklaringer. Her sker noget centralt. Vi bruger ikke modellens egne forklaringer. Empirisk viste det sig, at modellen underrapporterer (den retter 7 fejl, men forklarer kun 2) og opfinder paragrafnumre, der lyder plausible, men er forkerte. I stedet sammenligner vi input og output ord-for-ord med en diff-algoritme og klassificerer hver ændring automatisk i 12 kategorier (nutids-r, komma foran ledsætning, manglende sammensætning osv.). Hver kategori har en verificeret RO5-paragrafhenvisning. Resultatet er deterministisk korrekte forklaringer, uanset hvad modellen selv påstår.
Designbeslutninger, der definerer systemet
Undervejs traf vi flere beslutninger, der adskiller systemet fra en naiv "send tekst til AI"-tilgang.
Ukendte ord blokerer aldrig. I den oprindelige plan skulle ukendte ord (ord, der ikke findes i COR) trigge et nyt forsøg, hvor modellen blev bedt om at omformulere. I praksis var det en katastrofe: modellen fulgte instruktionen for godt og fjernede fagtermer eller egennavne fra teksten. "Vi bruger USPTO's database" blev til "Vi bruger patentdatabasen" - korrekt dansk, men forkert betydning. Løsningen: ukendte ord genererer en advarsel, men blokerer aldrig. Systemet er en korrekturlæser, ikke en censor.
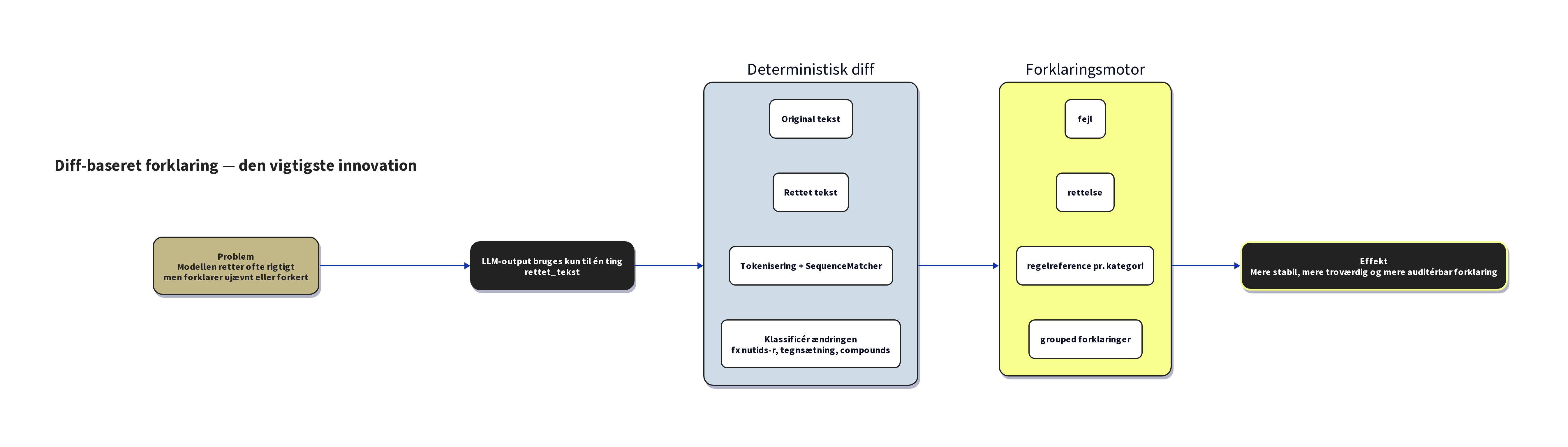
Modellens forklaringer er udskiftet med diff. De fleste AI-systemer stoler på modellens selvrapportering. Vi gør det modsatte: modellen producerer korrekt tekst (det er den trænet til), og pipelinen udleder forklaringerne deterministisk bagefter. Det er billigere, hurtigere og vigtigst af alt: det er korrekt. Ingen hallucinerede paragrafnumre.
Kun NOUN+NOUN-sammensætninger. Systemet fanger "patent ansøgning" → "patentansøgning", men det fanger bevidst ikke "lang tur" → "langtur". Selvom "langtur" er en gyldig COR-lemma, er "lang tur" (en tur, der er lang) en helt anden betydning end "langtur" (en type rejse). ADJ+NOUN-par er udelukket fra compound-detektionen for at undgå denne klasse af false positives.
Betydningsbevarelse er den hårdeste regel. Systemets prompt indeholder absolutte regler: "Du må ALDRIG erstatte et indholdsord med et andet ord." Substantiver, verber og adjektiver må kun ændres i bøjning eller stavning, aldrig i semantisk kerne. Hvis modellen er i tvivl, skal den lade være. Det giver et konservativt system med lavere recall (47 %), men med det allervigtigste tal: 0 % falske rettelser på korrekt tekst.
Resultater og hvad de betyder
Vi evaluerede systemet på 50 tilfældige testtekster med kendte fejl og ground-truth-rettelser. Tallene fortæller en klar historie.
Præcisionen på tekstniveau er 90%: i 9 ud af 10 tekster matcher den rettede tekst præcis, hvad en menneskelig dansklærer ville producere. Systemet retter aldrig korrekt tekst (0 % falske rettelser), og 96% af alle forespørgsler konvergerer uden problemer. Medianhastigheden er ca. 10 sekunder pr. tekst.
Recall er 47 %, og det er et bevidst valg. Systemet fanger knap halvdelen af alle ground-truth-fejl, men de fejl, det fanger, fanger det korrekt. For en retskrivningsassistent er det vigtigere ikke at ødelægge korrekt tekst end at fange absolut alle fejl. En kollega, der råber "fejl!" på korrekte ord, er værre end en, der overser en subtil pausekomma.
Baseline uden pipeline (modellen alene) havde en præcision på 76,6 %. De tre valideringslag løftede det til 90 %. Det er den konkrete gevinst ved at bygge en pipeline omkring modellen i stedet for bare at bruge den rå.
Hvad det kan bruges til, og hvad det ikke kan
Systemet er bygget til virksomheder, der producerer dansk tekst i stor mængde og har behov for korrekthed og fortrolighed: marketingafdelinger, der skriver blogindlæg; HR-konsulenter, der formulerer jobopslag; jurister, der finpudser klausuler, og sagsbehandlere i kommuner, der sender afgørelser til borgere.
Det er vigtigt at sige klart, hvad systemet ikke er. Det oversætter ikke. Det omformulerer ikke. Det foreslår ikke bedre ord. Det er en retskrivningsassistent, der retter grammatik, tegnsætning og stavning efter officielle regler og forklarer, hvorfor. Din stemme, dine ord og dit budskab bevares 100 %.
For virksomheder med krav om databeskyttelse er det lokale aspekt afgørende: teksten forlader aldrig maskinen. Ingen databehandleraftale, ingen overførsel til tredjeland, ingen per-brug-omkostning. Bare en computer på et skrivebord, der taler rigtig godt dansk.
Systemet kører i dag. Næste skridt er en virksomhedsspecifik termordbog (så "Consile" aldrig ender som "consile"), integration med eksisterende værktøjer via API og en stilguidefunktion, der håndhæver virksomhedens egne skriveregler.
Ændringslog
Fra original tekst via Opus 4.6 Extended bliver der modtaget disse rettelser (ca. 55 stk.)
Komma foran ledsætninger (§ 51) — 25+ rettelser: Konsekvent tilføjet komma foran "der", "som", "hvor", "hvad", "hvordan", "at", "hvorfor" i relativsætninger og ledsætninger. Største enkeltkategori.
Sammensætninger skrevet som ét ord (§ 18) — 9 rettelser:
- "fine-tunet" → "finetunet" (konsekvent i alle forekomster)
- "fine-tuningen" → "finetuningen"
- "kerne-ordforrådet" → "kerneordforrådet"
- "infinitiv-position" → "infinitivposition"
- "modal-verbum" → "modalverbum"
- "inferens-server" → "inferensserver"
- "under-rapporterer" → "underrapporterer"
- "term-ordbog" → "termordbog"
- "stil-guide-funktion" → "stilguidefunktion"
Komma ved helsætninger (§ 47-48) — 3 rettelser:
- "fejl men" → "fejl, men"
- "plausible men" → "plausible, men"
Øvrige kommarettelser (§ 41-56) — 5 rettelser:
- "sekunder afhængigt" → "sekunder, afhængigt"
- "retskrivning trænede" → "retskrivning, trænede"
- "data det" → "data, det"
- "systemet om" → "systemet, om"
- "sikre at" → "sikre, at"
Stort/lille bogstav (§ 12-17) — 2 rettelser:
- "Retskrivningsreglerne" → "retskrivningsreglerne" (generisk brug)
- "Low-Rank Adaptation" → "low-rank adaptation"
Sammensætninger ét ord (yderligere):
- "Marketing-afdelinger" → "marketingafdelinger"
- "fejl-par" → "fejlpar"
- "navneords-par" → "navneordspar"
- "fuge-s" → "fuges"
Oxford-komma fjernet:
- "version, og en forklaring" → "version og en forklaring"
- "via API, og en" → "via API og en"
Procent-tegn med mellemrum:
- "90%" → "90 %" (konsekvent, dansk standard)
Bevidst IKKE accepterede rettelser
| Forslag | Beholdt som | Begrundelse |
|---|---|---|
| "100 sprog" → "hundrede sprog" | "100 sprog" | Tal i blog-kontekst er standard |
| "NOUN+NOUN" → "noun+noun" | "NOUN+NOUN" | Teknisk label, caps er konvention |
| "ADJ+NOUN" → "adj+noun" | "ADJ+NOUN" | Samme |
| "ALDRIG" → "aldrig" i citat | "ALDRIG" | Bevidst emfase i citeret prompt-tekst |
| "open-source" → "open source" | "open source-" (attributivt) | Accepteret delvist: bruger "open source" som selvstændigt, men "open source-sprogmodel" med bindestreg som attributiv sammensætning |
| Retoriske fragmenter samlet til liste | Beholdt som fragmenter | Stilistisk virkemiddel |
Fortsæt læsningen

Hvad er Fable 5 og GPT-5.6 Sol
De fleste "Hvad er AI?"-artikler starter med en robot og en glaskrukke. Vi springer den over. Den vigtigste historie om sommerens to nye fro…

Cloudflare laver reglerne for AI-trafik om
Der er ved at ske et skifte i måden, hele internettet håndterer AI-trafik på. Det er større end en produktopdatering. Cloudflare, der sidder…
906 kald senere: Hvad køber du egentlig for mere effort i Opus 4.8?
En praktisk analyse af kvalitet, tokenforbrug og svartid, målt på et almindeligt Claude-abonnement, ikke i et laboratorium. Datagrundlag: 90…