
Ni år i træk har Stanford Institute for Human-Centered AI udgivet sin AI Index-rapport. Det er det tætteste feltet kommer på et uafhængigt, datadrevet regnskab over, hvad der faktisk foregår. 2026-udgaven landede i dag, og den er den hidtil…

Ni år i træk har Stanford Institute for Human-Centered AI udgivet sin AI Index-rapport. Det er det tætteste feltet kommer på et uafhængigt, datadrevet regnskab over, hvad der faktisk foregår. 2026-udgaven landede i dag, og den er den hidtil mest substansrige.
Vi har læst hele rapporten og gennemgår den her sektion for sektion. Ikke som et pressemeddelelses-referat, men som en analyse der kombinerer de tekniske fund med det der faktisk har konsekvens for virksomheder og fagfolk der arbejder seriøst med AI. Forventningen er, at du kender feltet, og ikke har brug for en blød introduktion til, hvad en stor sprogmodel er.
Hvad Stanford AI Index er, og hvorfor den skiller sig ud fra al anden AI-rapportering
De fleste AI-rapporter i 2026 produceres af virksomheder med en kommerciel interesse i konklusionerne. Stanford AI Index er anderledes. Den er produceret af Stanford Institute for Human-Centered AI, er nu i sin 9. udgave og har opbygget sin metodologi med et eksplicit mål om uafhængighed. Rapporten dækker ni kapitler: Research & Development, Technical Performance, Responsible AI, Economy, Science, Medicine, Education, Policy & Governance og Public Opinion. Det er en bredde der langt overstiger enhver vendor-rapport, og den kombinerer data der normalt behandles i siloer.
Metodologisk bygger rapporten på primærdata: patentanalyse fra USPTO og WIPO, akademiske publikationer på tværs af millioner af artikler, benchmarkresultater fra anerkendte evalueringsmiljøer, investeringstal fra Pitchbook og CB Insights og globale holdningsundersøgelser. Stanford er selv ærlige om begrænsningerne. De har i denne udgave inkluderet en eksplicit kritik af de benchmarks der bruges til at måle AI-fremgang, herunder at populære math-benchmarks har en fejlrate på 42%. Det er en selvkritik der er usædvanlig i et felt domineret af selvreklame.
2026-udgaven er særlig vigtig fordi den er den første store syntese af, hvad rigtige deployments faktisk leverer. AI er ikke længere kun i laboratoriet. Data fra hospitaler, softwareteams og virksomheders regnskaber er nu tilgængeligt som systematisk analyseret evidens, og den adskiller sig fra det der kom ud af kontrollerede tests på vigtige punkter. Læs den fulde rapport her hvis du vil ned i primærdata selv.
Kapacitet: Plateau-hypotesen er aflivet, men billedet er komplekst
Det spørgsmål alle har stillet det seneste år er, om AI-udviklingen er ved at bremse op. Stanford-rapporten besvarer det direkte: nej. Foundation models forbedrer sig fortsat på tværs af næsten alle målte dimensioner, og på centrale fronter er tempoet accelererende. Det mest konkrete eksempel er SWE-bench Verified, det kodebenchmark der tester, om AI kan løse rigtige fejl i eksisterende open source-software under produktionsagtige betingelser. Her steg performance fra 60% til tæt på 100% på ét enkelt år. Det er ikke en marginal fremgang. Det er en teknologi der er gået fra "nyttig som assistent" til "produktionsklar som selvstændig løser" i én benchmark-cyklus.
AI-agenter er det andet område med dramatisk dokumenteret vækst. Succesraten for agenter der løser rigtige computeropgaver på tværs af operativsystemer steg fra 20% i 2025 til 77,3% ifølge Terminal-Bench. Inden for cybersikkerhed løste AI-agenter problemer 93% af gangene mod 15% i 2024. Og i et af de mest symbolsk ladede resultater: Googles Gemini Deep Think vandt en guldmedalje ved International Mathematical Olympiad 2025.
Det er kapaciteter der for to år siden befandt sig i kategorien "inden for ti år måske."
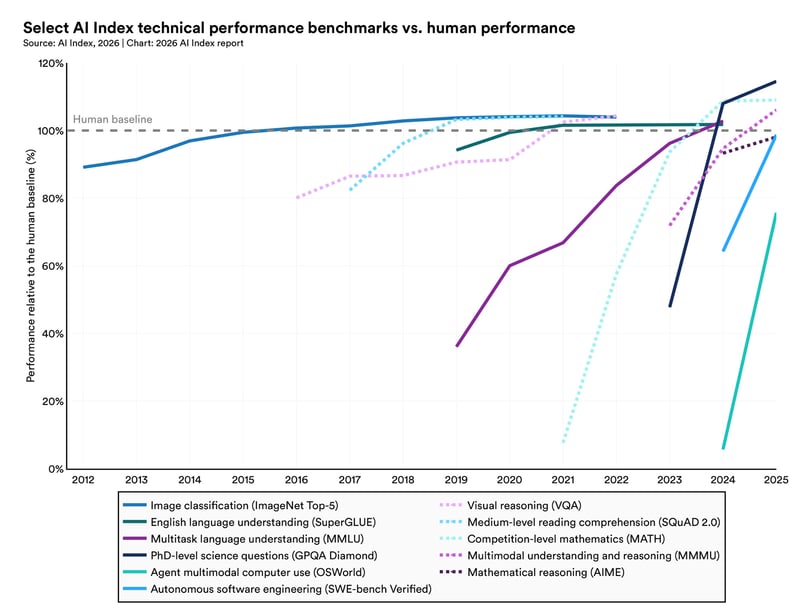
Men rapporten introducerer også et begreb der er mindst ligeså vigtig som fremgangstallene: den ujævne frontier. Det beskriver et mønster der er grundlæggende for at forstå AI's nuværende tilstand. Den model der vandt olympiade-guldmedaljen, aflæser et analogt ur korrekt blot 50,1% af gangene. En opgave ethvert barn klarer. Robotter lykkes kun med 12% af rigtige husholdningsopgaver som at folde tøj eller vaske op. AI halter stadig på at lære fra video, generere sammenhængende langt-form video, håndtere kompleks flertrinssplanlægning, og lave finansiel analyse i produktion. Det er et mønster uden åbenlys logik, og rapporten er ærlig om, at vi ikke har en god forklaring på det.
For enhver der implementerer AI i produktionsmiljøer, er den ujævne frontier ikke en akademisk nysgerrighed. Det er den vigtigste enkeltfaktor til at forklare, hvorfor AI-projekter fejler. Fordi en model imponerer i ét benchmark, generaliserer det ikke til en naboopgave. Det er grunden til, at evaluering på egne use cases under egne produktionsbetingelser er den eneste troværdige metode til at vurdere en models egnethed. Vendor-benchmarks, selv de velrenommerede, er nødvendigt men utilstrækkeligt. Stanford-rapporten dokumenterer dette systematisk for første gang, og dens konklusion er klar: en model med 99% på SWE-bench kan have et blindt punkt på netop det problem du sidder med.
USA vs. Kina: Et kapløb der har skiftet karakter grundlæggende
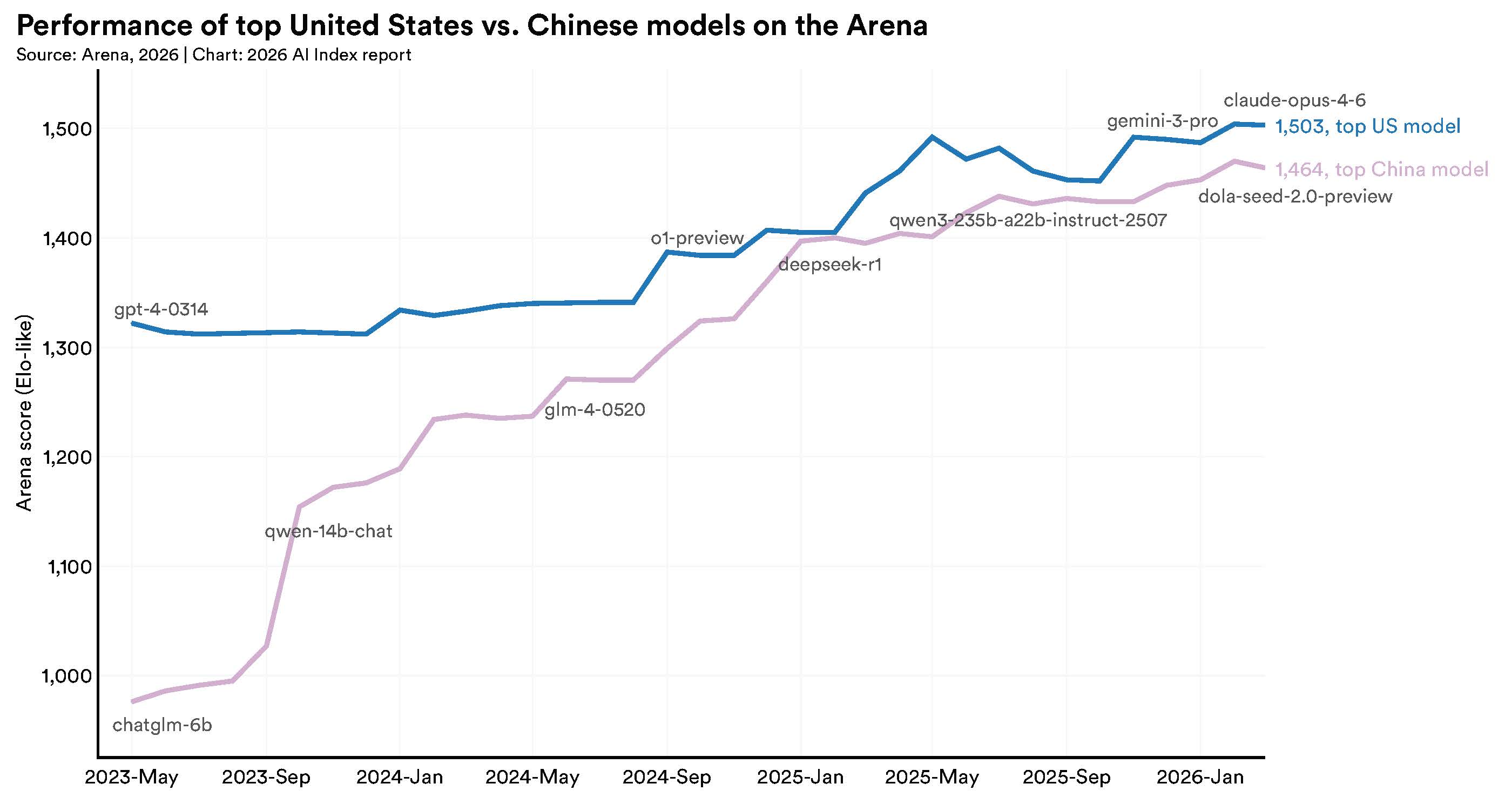
I 2023 var den amerikanske AI-forspring stor og synlig. OpenAIs ChatGPT var et generationsskift uden kinesisk pendant. Det billede er nu dramatisk anderledes. Arena-rangeringen, der bruges i rapporten og er baseret på menneskelige præferencer på tværs af millioner af side-by-side sammenligninger, viser, at USA og Kina har byttet pladser øverst adskillige gange siden tidligt 2025. I februar 2025 matchede DeepSeek-R1 kortvarigt den bedste amerikanske model.
Pr. marts 2026 fører Anthropics topmodel med 2,7%. Det er statistisk et set-point, ikke en meningsfyldt kapacitetsforskel i produktionsbrug.
Det er dog ikke et simpelt "Kina vinder"-narrativ, og rapporten er eksplicit om det. De to lande konkurrerer på fundamentalt forskellige dimensioner. USA producerer stadig flest top-tier modeller og de mest citerede AI-patenter. Kina fører på absolut publikationsvolumen, samlet antal patenter, citationsvolumen og antal installerede industrirobotter.
Sydkorea er et tredje aktiv der sjældent nævnes i kapløbs-narrativet: landet er fremstået som verdensleder i innovationstæthed og filer nu flere AI-patenter per capita end noget andet land. Det er ikke et topoløb. Det er et flerdimensionalt konkurrencelandskab med mindst tre alvorlige aktører og en lang række nationalt ambitiøse følgere.
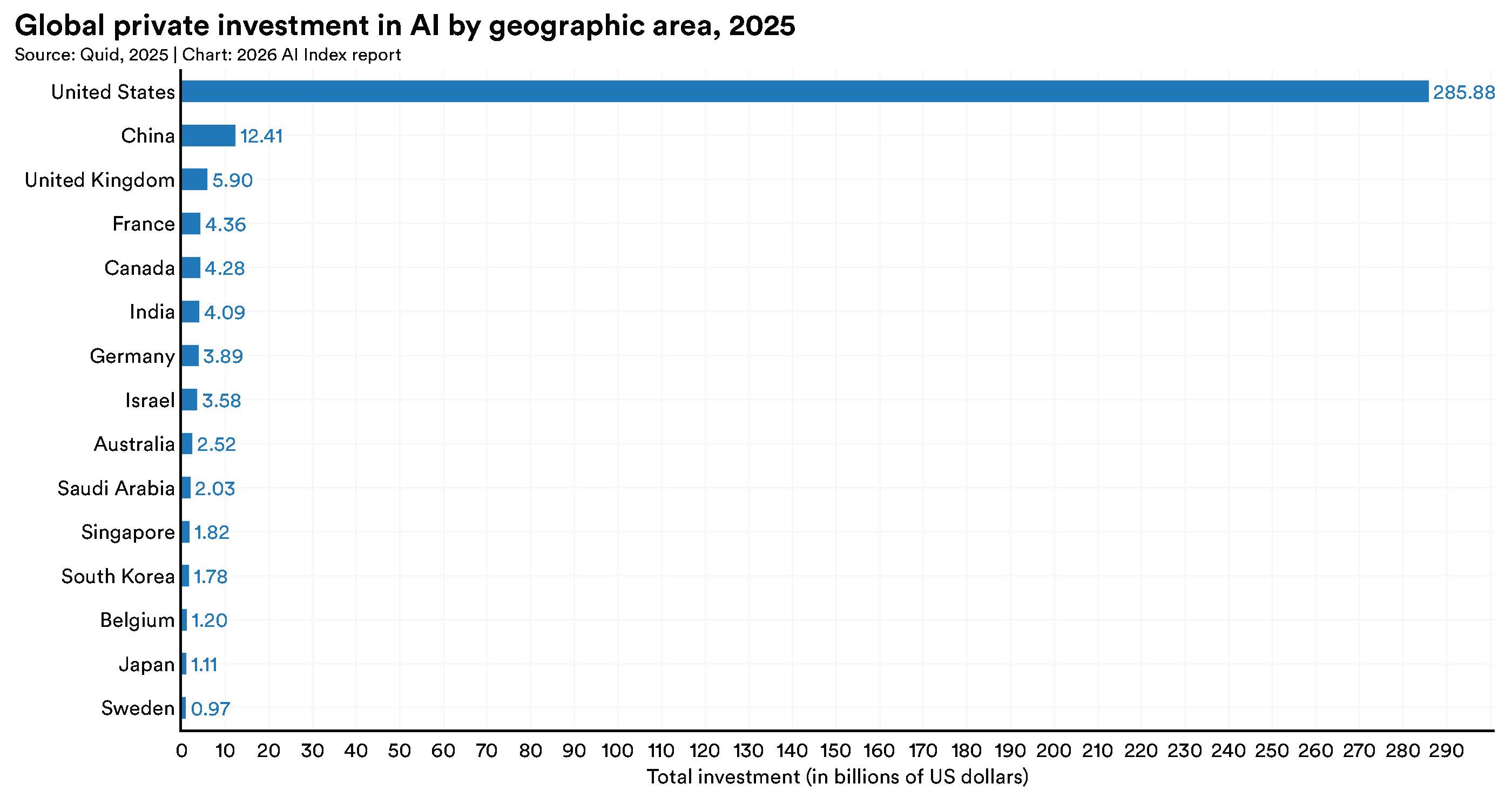
Investeringstallene skaber en umiddelbar asymmetri: USA's private AI-investeringer nåede 285,9 mia. dollar i 2025, 23 gange mere end Kinas 12,4 mia. dollar. Men Stanford-rapporten er eksplicit om, at denne sammenligning undervurderer Kinas reelle kapital. Den kinesiske stat kanaliserer ressourcer via statslige investeringsfonde der ikke optræder som private investeringer i standardstatistik. Rapporten estimerer, at 912 mia. dollar fra sådanne fonde er rullet ud på tværs af industrier inklusive AI fra 2000 til 2023. Holder man den faktor for øje, er det samlede billede markant tættere end de private investeringstal alene antyder.
To faktorer definerer USA's fremtidige AI-position mere end noget benchmark: talent og hardware. Antallet af AI-forskere og udviklere der migrerer til USA er faldet 89% siden 2017, og 80% af det fald er sket alene det seneste år. Det er ikke en ydre faktor der truer en stærk position. Det er en fundamental ændring i, hvem der bygger de næste generation af modeller og i hvilke lande. Og TSMC-afhængigheden er den anden side af samme mønt: næsten alle verdens ledende AI-chips fabrikeres af ét firma på én ø. Et TSMC-anlæg i USA begyndte drift i 2025, men kapacitetsopbygning måles i årtier, ikke år. For enhver der tænker i AI-forsyningskæde-risici, er det den vigtigste enkeltfaktor i hele rapporten.
Infrastruktur og energi: Tallene bag modellerne ingen taler om
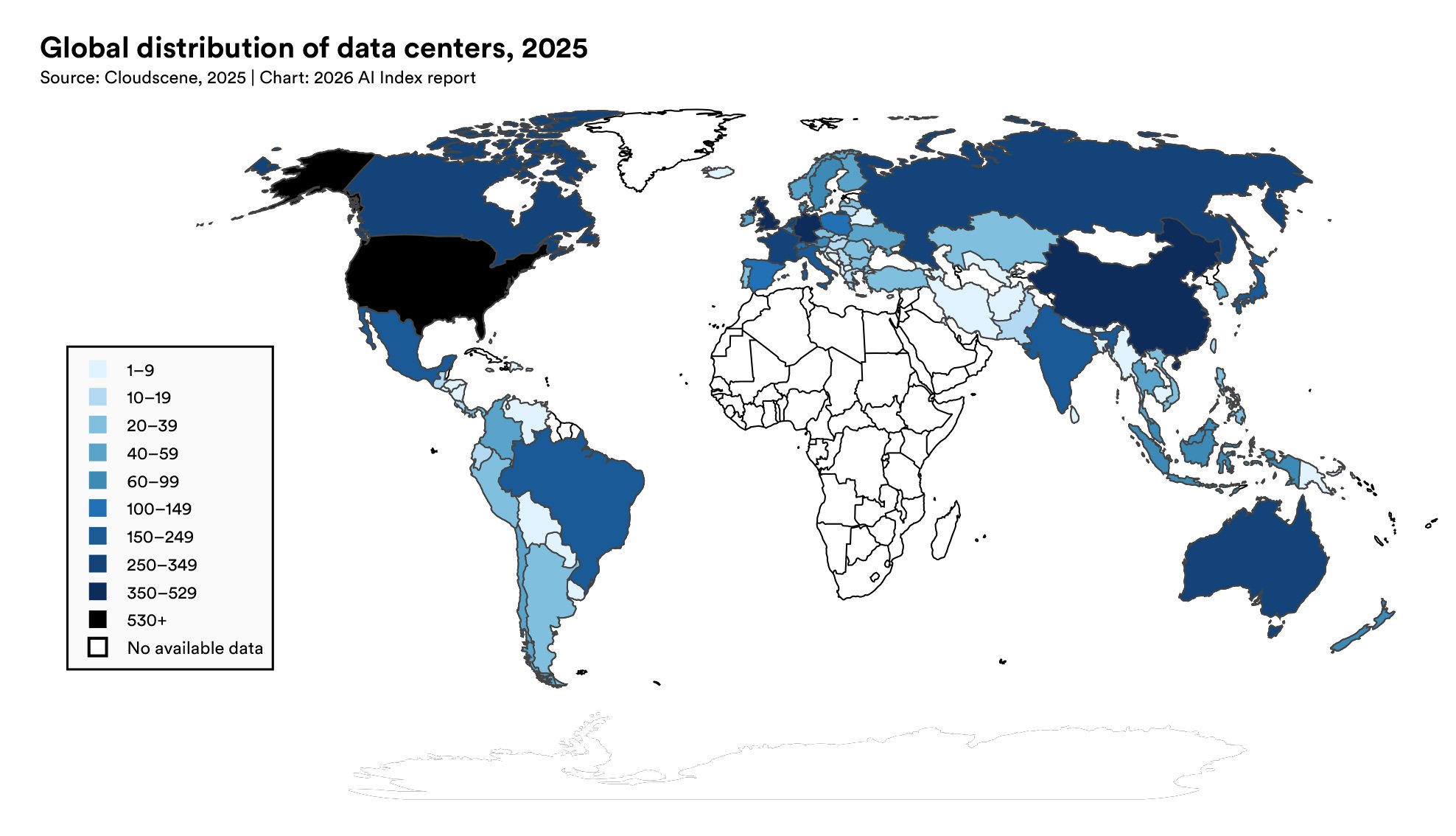
Et kapitel der fortjener langt mere opmærksomhed end det typisk får, handler om den fysiske infrastruktur bag AI. USA huser 5.427 AI-datacentre, mere end 10 gange ethvert andet land. Den samlede AI-datacenter-kapacitet er vokset til 29,6 GW, svarende omtrent til peak-energiforbruget i hele delstaten New York. Det er den fysiske maskineri bag de chatbots og produktionsmodeller vi bruger dagligt. Og dens vækst er eksponentiel i et tempo, der overstiger hvad energiinfrastrukturen mange steder er dimensioneret til.
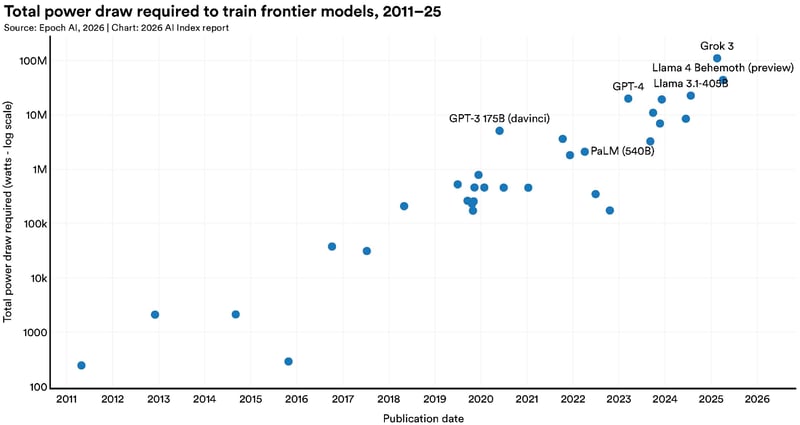
Miljøomkostningerne er for første gang dokumenteret i rapporten med en detalje der giver præcise tal at forholde sig til. Grok 4's estimerede CO2-udledning under træning nåede 72.816 tons CO2-ækvivalent. Det svarer til drivhusgasudledningen fra 17.000 biler i et helt år. GPT-4o's vandforbrug til inference alene kan overstige drikkevandsbehov for 12 millioner mennesker. Det er ikke marginale eksternaliteter. Det er infrastrukturomkostninger af en skala der hører hjemme i en ESG-vurdering, og som er slående fraværende fra langt de fleste virksomheders AI-strategidiskussioner.
TSMC-koncentrationsrisikoen fortjener sin egne sektion. Næsten alle de chips der driver verdens ledende AI-modeller, produceres af ét firma på én ø i et geopolitisk ustabilt område. Det er en forsyningskæde-sårbarhed uden sidestykke i moderne teknologihistorie. Et TSMC-anlæg i Arizona begyndte drift i 2025, men det er ét anlæg mod en global efterspørgsel der vokser med over 100% om året. Rapporten er diplomatisk men klar om implikationerne: den globale AI-hardware-forsyningskæde er ikke resilient, og ingen seriøs AI-strategi kan ignorere det.
For virksomheder der bygger AI-strategier er energi og infrastruktur gået fra irrelevant til et faktisk driftsparameter på to fronter. Den første er bæredygtighedsrapportering: GPU-compute har et energifootprint der er synligt i CO2-regnskaber, og regulering på det område strammes. Den anden er kapacitet og pris: cloud-AI-kapacitet er ikke ubegrænset, og prisen på frontier-model-inferens har varieret dramatisk som funktion af præcis den infrastruktur rapporten beskriver. Forståelsen af, at det ikke er gratis at køre en frontier-model, er relevant for enhver budget-model for AI i produktion.
Økonomi og adoption: Pengene strømmer, gevinsterne fordeler sig ujævnt
Globale virksomhedsinvesteringer i AI ramte 581,7 mia. dollar i 2025, en stigning på 130% fra foregående år. Private investeringer nåede 344,7 mia. dollar, en stigning på 127,5%. Der blev grundlagt 1.953 nyfinansierede AI-virksomheder i USA alene i 2025, mere end 10 gange antallet i det næst-højeste land. Det er investeringstal der ikke har historisk sidestykke i nogen teknologibølge, inklusive dotcom-æraen, og de sætter konteksten for alt det øvrige i rapporten: AI er ikke et forskningsprojekt. Det er den største kapitalallokering i teknologihistorien.
Adoptions-tallene er fascinerende i deres ujævnhed. Generativ AI nåede 53% global befolkningsadoption inden for tre år, hurtigere end pc'en og hurtigere end internettet. Men adoptionen korrelerer stærkt med BNP per capita og er langt fra ensartet. Singapore er på 61%, UAE på 54%, mens USA rangerer som nummer 24 med 28,3%. Den estimerede forbrugerværdi af generative AI-værktøjer for amerikanske brugere nåede 172 mia. dollar om året i begyndelsen af 2026, med medianværdi per bruger tredoblet fra 2025 til 2026. Den tredobling er bemærkelsesværdig: det er brugere der eksisterer i systemet fra begyndelsen og finder mere og mere value over tid.
PwC's parallelstudie refereret i rapporten dokumenterer det mønster der er mest kritisk for enhver AI-strategi: 74% af AI's samlede økonomiske gevinst tilfalder 20% af virksomhederne. Det er ikke tilfældigt. De virksomheder der fanger gevinsten, bruger ikke blot flere AI-værktøjer end de øvrige. De bruger AI som katalysator for forretningsfornyelse og adgang til nye omsætningskilder, ikke primært til effektivisering af eksisterende processer.
Effektiviseringsgevinster er lavthængende og midlertidige, fordi konkurrenterne henter dem med en tidsforsinkelse der krymper for hvert kvartal. Forretningsmodel-transformation er strukturel og sværere at kopiere.
Den vigtigste praktiske implikation af disse to tal er, at adoption i sig selv ikke er differentieringen i 2026. De fleste virksomheder i dit marked bruger nu AI i en eller anden form. Spørgsmålet er ikke om, men hvad og til hvad. Virksomheder der sætter AI på eksisterende processer uden at ændre selve forretningslogikken, er i den 80% der deler de resterende 26% af den samlede gevinst. Det er ikke en komfortabel position, og rapporten efterlader ingen tvivl om, at gabet ikke mindskes af sig selv.
Jobmarkedet: Den strukturelle forandring der allerede er i gang
Rapporten er usædvanligt konkret og ærlig på et område mange foretrækker at formulere med maksimal tvetydighed. Den centrale observation er tydelig og understøttet af beskæftigelsesdata: produktivitetsgevinster fra AI optræder i præcis de samme fagområder, hvor entry-level beskæftigelse begynder at falde. Det er ikke et tilfældighedernes spil. Beskæftigelse blandt softwareudviklere på 22-25 år er faldet næsten 20% siden 2024, selv mens headcount for udviklere over 30 år fortsætter med at vokse. Mønstret gentager sig i kundeservice og i andre roller med høj AI-eksponering.
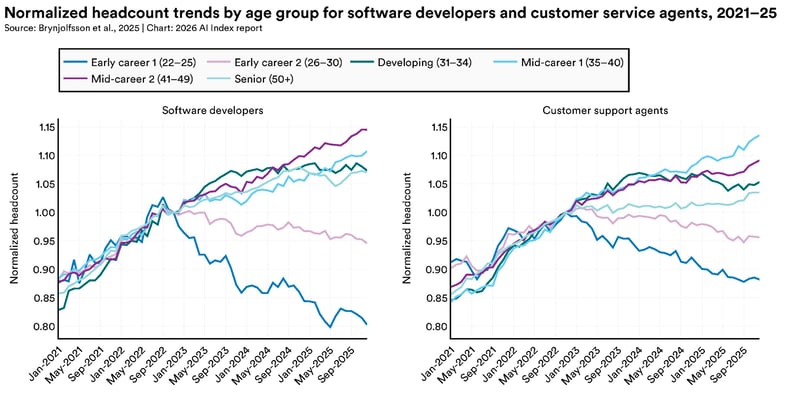
Produktivitetsgevinsterne er veldokumenterede og reelle: 14% i kundeservice, 26% i softwareudvikling ifølge de studier rapporten refererer. Men mønstret er det vigtige. Gevinsterne er størst i de strukturerede, veldefinerede og repetitive dele af jobbet. Det er præcis de dele der traditionelt udgør juniorrollen. AI er en meget effektiv juniormedarbejder for bestemte typer opgaver, og den observation driver beskæftigelsesfaldet i den yngste aldersgruppe. Gevinster med opgaver der kræver domænejudgement, relationsforståelse og kontekstuel navigation er derimod svage eller negative i rapporten.
Virksomhedsundersøgelser i rapporten peger entydigt fremad. Planlagte headcount-reduktioner overstiger allerede de faktiske historiske reduktioner, og McKinseys 2025-undersøgelse viser, at en tredjedel af organisationer forventer, at AI vil skrumpe deres arbejdsstyrke i det kommende år, særligt i kundeservice, supply chain og softwareudvikling. Det er ikke prognoser fra pessimister. Det er kapitalmarkedsrationer fra ledere der aflægger regnskab til analytikere, og de har konsekvenser for den samlede efterspørgsels- og kompetencedynamik i disse sektorer.
Det der ikke diskuteres tilstrækkeligt i den brede debat, er den strukturelle konsekvens for kompetenceudvikling. Seniorroller opstår typisk af juniorroller, og den læringssti er ikke triviel at erstatte. Når juniorpositionerne forsvinder, er det ikke blot tab af billig arbejdskraft. Det er et brud på den pipeline der producerer seniorkompetence med fem til ti års forsinkelse. Det er et problem rapporten dokumenterer men ikke løser. Virksomheder der stadig ansætter og oplærer juniorer, bygger en konkurrencefordel der ikke er synlig i et regneark i dag, men som er meget konkret i 2030.
Transparens og ansvarlig AI: Det der ikke holder trit med kapacitetsudviklingen
Foundation Model Transparency Index måler, hvor åbent store AI-virksomheder oplyser om deres modellers træningsdata, beregningsressourcer, kapaciteter, risici og brugspolitikker. I 2026-rapporten faldt gennemsnitsscoren fra 58 til 40 point. Det er ikke en marginal nedgang. Det er et felt der bevæger sig i den forkerte retning systematisk, og mønstret er klart: de mest kapable modeller er de mindst transparente. Google, Anthropic og OpenAI har alle opgivet praksis med at oplyse datasætstørrelser og træningstid. 80 af de 95 mest bemærkelsesværdige modeller lanceret i 2025 blev frigivet uden træningskode. Industrien er vokset mere magtfuld og er blevet mere lukket i samme bevægelse.
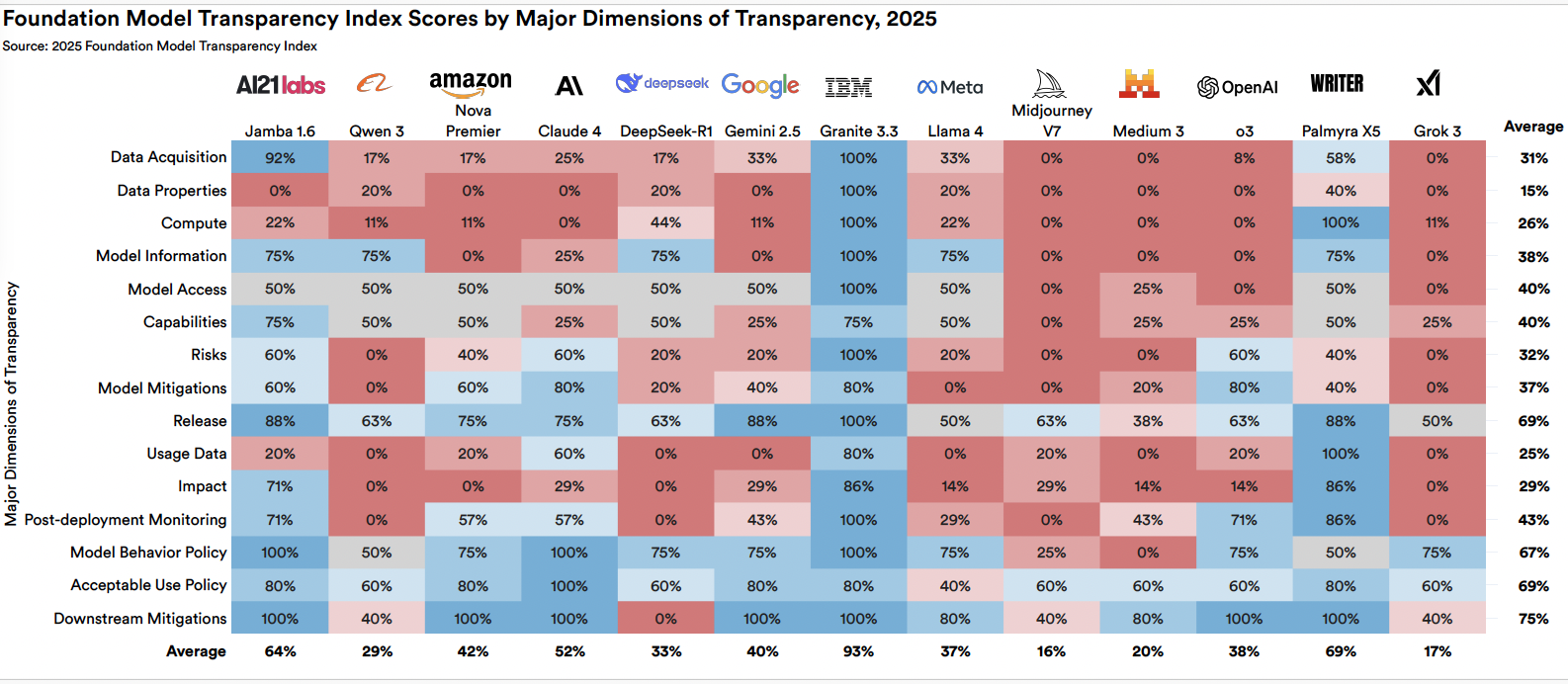
Ansvarlig AI er et begreb alle bruger, men rapporten dokumenterer, at den faktiske implementering halter massivt efter kapacitetsudviklingen. Næsten alle frontier-modeludviklere rapporterer resultater på kapacitetsbenchmarks, men rapportering på ansvarlige AI-benchmarks er sporadisk, inkonsistent og ofte selektiv. Dokumenterede AI-hændelser steg til 362 i 2025, op fra 233 i 2024. Og ny forskning tilføjer en ekstra kompleksitet der er svær at navigere: forbedring af ét ansvarligt AI-parameter som sikkerhed kan systematisk forringe et andet som nøjagtighed. Det er ikke et ingeniørproblem med en klar løsning. Det er et strukturelt tradeoff der kræver eksplicit governance og ikke kan løses med et enkelt benchmark.
For europæiske virksomheder er dette relevant i en juridisk meget konkret forstand. EU AI Act trådte i fuld håndhævelse i januar 2026, og 89 af 156 globale håndhævelseshandlinger inden for AI er koncentreret i EU. Compliance-omkostninger varierer op til otte gange på tværs af jurisdiktioner. Kun 12 af 47 lande med aktiv AI-lovgivning har reelle håndhævelsesmekanismer. Det er et reguleringslandskab der er dyrt, fragmenteret og med EU som den eneste jurisdiktion der pt. reelt håndhæver. AI-industri-repræsentanter er i rapporten dokumenteret til at have tredoblet deres andel af vidner i amerikanske kongreshøringer siden 2017, mens uafhængige akademikere er faldet markant. Lobbyinteressen har aldrig været højere.
For AI-indkøbere og implementeringspartnere er konsekvensen af transparens-faldet konkret: du kan ikke validere, hvad der er i den model du deployerer. Du har ikke adgang til at vide, hvilke data den er trænet på, og du har ikke et grundlag for uafhængig risikovurdering baseret på producent-dokumentation alene. Det er et due diligence-problem af en art virksomheder ikke er vant til fra traditionelle software-indkøb. Vendor-dokumentation er ikke tilstrækkelig, og uafhængig testing på egne data og scenarier er den eneste reelle alternative tilgang til at forstå, hvad du faktisk har købt.
Videnskab, medicin og uddannelse: Tre meget forskellige historier om AI i praksis
Rapporten har to nye kapitler i år om AI i videnskab og medicin, og de er værd at læse præcist fordi de viser den enorme variation i, hvad AI faktisk leverer på tværs af domæner. I videnskab er AI rykket fra assistance til faktisk opdagelse på visse fronter. AI-relaterede publikationer i naturvidenskab, fysik og livsvidenskaber steg alle 26-28% år over år. De konkrete gennembrud inkluderer: For første gang kørte AI en komplet vejrudsigningspipeline fra ende til anden, fra rå realtids-meteorologiske observationer til færdige prognoser for temperatur, vind og luftfugtighed, uden menneskelig mellemkomst. Astronomi byggede sin første foundation model der automatiserer observationer på tværs af 10 teleskoper. Det er ikke AI der hjælper videnskabsmænd med at skrive papirer. Det er AI der udfører eksperimentelle opgaver selvstændigt.
Medicinkapitlet fortæller to meget forskellige historier der begge er vigtige at holde adskilt. Den positive: Kliniske noter-systemer der automatisk genererer notater fra patientbesøg, opnåede udbredt adoption i 2025. På tværs af hospitalssystemer rapporterede læger op til 83% reduktion i tid brugt på noter og markante reduktioner i udbrændthed. Det er en målbar, dokumenteret gevinst med direkte klinisk og personalemæssig effekt. Den kritiske: En systematisk gennemgang af over 500 kliniske AI-studier fandt, at næsten halvdelen baserede sig på eksamensspørgsmål og ikke rigtige patientdata. Blot 5% brugte reelle kliniske data. Evidensbasen er langt svagere end den opmærksomhed teknologien modtager, og rapporten påpeger det eksplicit.
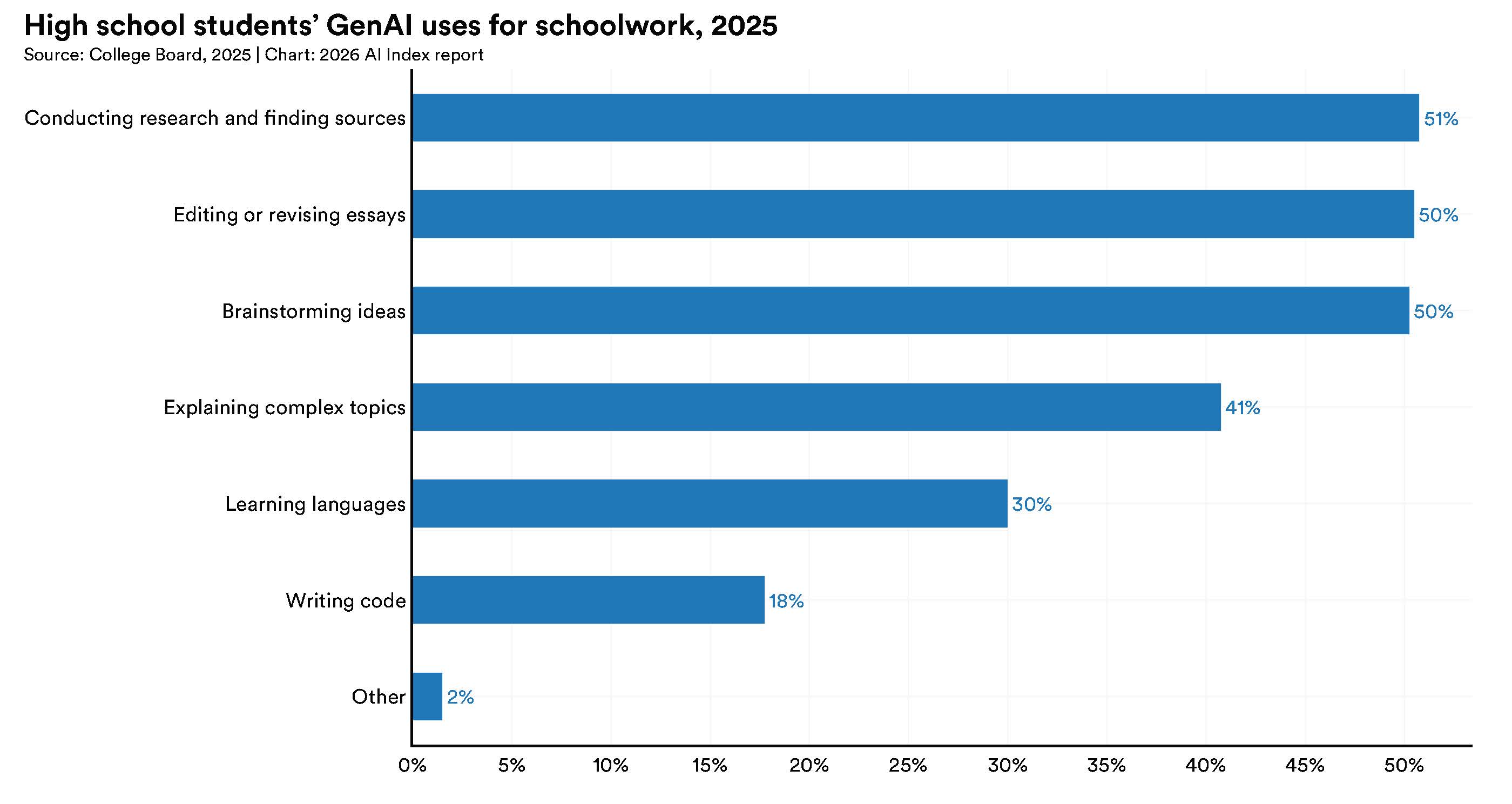
Uddannelseskapitlet dokumenterer en kløft der vokser i realtid og er udtryk for noget strukturelt. Fire ud af fem amerikanske gymnasie- og universitetsstuderende bruger nu AI til skoleformål. Antallet af nye AI-ph.d.-uddannede i USA og Canada steg 22% fra 2022 til 2024. Men kun halvdelen af skolerne har AI-politikker, og blot 6% af lærerne siger, at disse politikker er klare. Den viden de studerende opbygger om AI, sker primært selvstændigt og ustruktureret. AI-literacy som kompetence er reelt i vækst, men det formelle uddannelsessystem har ikke indhentet teknologiens tempo, og det er et gap der vil tage et årti at lukke.
Det samlede billede på tværs af de tre domæner er, at AI er bevist effektiv i specifikke, veldefinerede og strukturerede opgaver: notat-generering, observationsautomatisering, kode-fejlrettelse, matematik. Og den er ikke-bevist eller aktivt under-performende på komplekse, domænespecifikke, vurderingsbaserede opgaver der kræver nuanceret kontekstforståelse. Det er den distinction der bør styre, hvor AI prioriteres i din organisation. Ikke det der imponerer i en demo. Det der er bevist i produktion, på egne data, under egne betingelser.
Fortsæt læsningen

JADEPUFFER: Første AI-drevne ransomware brugte et år gammelt hul
En AI-agent hackede sig ind, stjal kodeord, krypterede en database og skrev sin egen løsesumsnote. Uden et menneske ved tastaturet undervejs…

Hvad er Fable 5 og GPT-5.6 Sol
De fleste "Hvad er AI?"-artikler starter med en robot og en glaskrukke. Vi springer den over. Den vigtigste historie om sommerens to nye fro…

Cloudflare laver reglerne for AI-trafik om
Der er ved at ske et skifte i måden, hele internettet håndterer AI-trafik på. Det er større end en produktopdatering. Cloudflare, der sidder…